Snake Learning -- A Communication- and Computation-Efficient Distributed Learning Framework for 6G
Manuscript Information
Xiaoxue Yu, Xingfu Yi, Rongpeng Li, Fei Wang, Chenghui Peng, Zhifeng Zhao and Honggang Zhang, “Snake Learning: A Communication- and Computation-Efficient Distributed Learning Framework for 6G,” IEEE Commun. Mag., Jan. 2025.
背景介绍
随着6G网络的快速发展,网络计算资源得到了进一步整合,智能用户设备(User Equipment,UE)和网络节点(Network Elements,NEs)不再只是数据的接收终端,还可以作为计算节点,参与网络智能化应用的协作计算。这种协作方式被称为“计算即服务”(Compute-as-a-Service,CaaS)和“AI即服务”(AI-as-a-Service,AIaaS)。在此背景下,6G将逐渐演化为一个动态的分布式计算平台,为网络智能和资源利用率的提升提供前所未有的机会。
为了提高网络的智能化水平,分布式深度学习成为一种重要的技术手段。当前主流的分布式学习框架,如联邦学习(Federated Learning,FL)、拆分学习(Split Learning),已经在一些场景,尤其是大模型微调方面,展示出了潜力。然而,在6G网络环境下,这些框架仍面临着不少难题,尤其是在高度异构、通信不稳定和资源受限的环境中更是困难重重。因此,设计一种高效的、能够适应6G网络环境的学习框架,是未来推动网络智能化发展的关键一步。
现有方法面临的挑战
目前,广泛应用的分布式学习框架,包括联邦学习、拆分学习及其各种混合变体,主要面临以下几大挑战:
- 对通信同步高程度依赖:联邦学习通常依赖多个设备与中心服务器之间频繁的双向通信来实现模型的同步,拆分学习更是需要在每一次学习过程中依靠通信传递中间激活值和梯度完成训练。这对于6G的无线网络环境来说并不理想,因为无线网络中的连接往往是不稳定的。环境变化、设备密度、设备移动性等因素都会导致上下行速率波动,从而影响实时数据和模型同步的稳定性。这种依赖同步通信的特性不仅增加了带宽的压力,还可能导致模型训练过程的不稳定,甚至无法收敛,从而严重影响分布式学习的效率和效果。
- 可用资源的异构性和动态性:6G网络中的计算资源是动态且异构的。服务节点的可用性会因为服务间共享而不断变化,导致所谓的“潮汐效应”,即资源的可用性随时间波动。这意味着一些节点在特定时间内可能无法提供足够的计算能力来满足复杂模型的训练需求。此外,不同供应商提供的计算节点硬件性能各异,导致计算能力的不均衡,这给分布式学习带来了额外的复杂性。
- 数据异质性:在分布式学习中,不同节点持有的数据通常存在显著差异,即非独立同分布(Non-IID)的情况。这种差异可能来自于用户的行为习惯、时间变化、地理位置等因素,导致各个节点在训练中面临不同的优化目标,影响模型的稳定性和泛化能力。单纯依赖数据增强或合成数据等传统手段难以有效解决这些问题,因此需要新的、更智能的训练策略。

图1: 不同分布式学习框架对比
Snake Learning:一种新型分布式学习框架
为了解决上述问题,我们提出了名为“Snake Learning”(蛇形学习)的新型分布式协同学习框架。该框架借鉴了经典游戏“贪吃蛇”的思路,逐层分配模型的中间部分给不同的节点进行训练,从而最大化利用6G网络中各节点的异构计算资源,降低通信和计算的负担。具体来说,Snake Learning 的核心理念是将模型的不同中间层分配给不同的节点来训练,而模型的第一层和最后一层由所有节点共同负责。其中,第一层提取基础特征,最后一层则用于任务的具体决策。每个节点在完成其负责的本地训练任务后,再将更新的参数上传,而不是实时同步所有节点的参数。通过这种逐层传递机制,以及必要的数据处理、蒸馏、自适应学习率等技术的应用,Snake Learning 显著减少了通信和计算资源的消耗,还能够在出现网络中断的情况下继续进行训练,具有极高的容错能力。
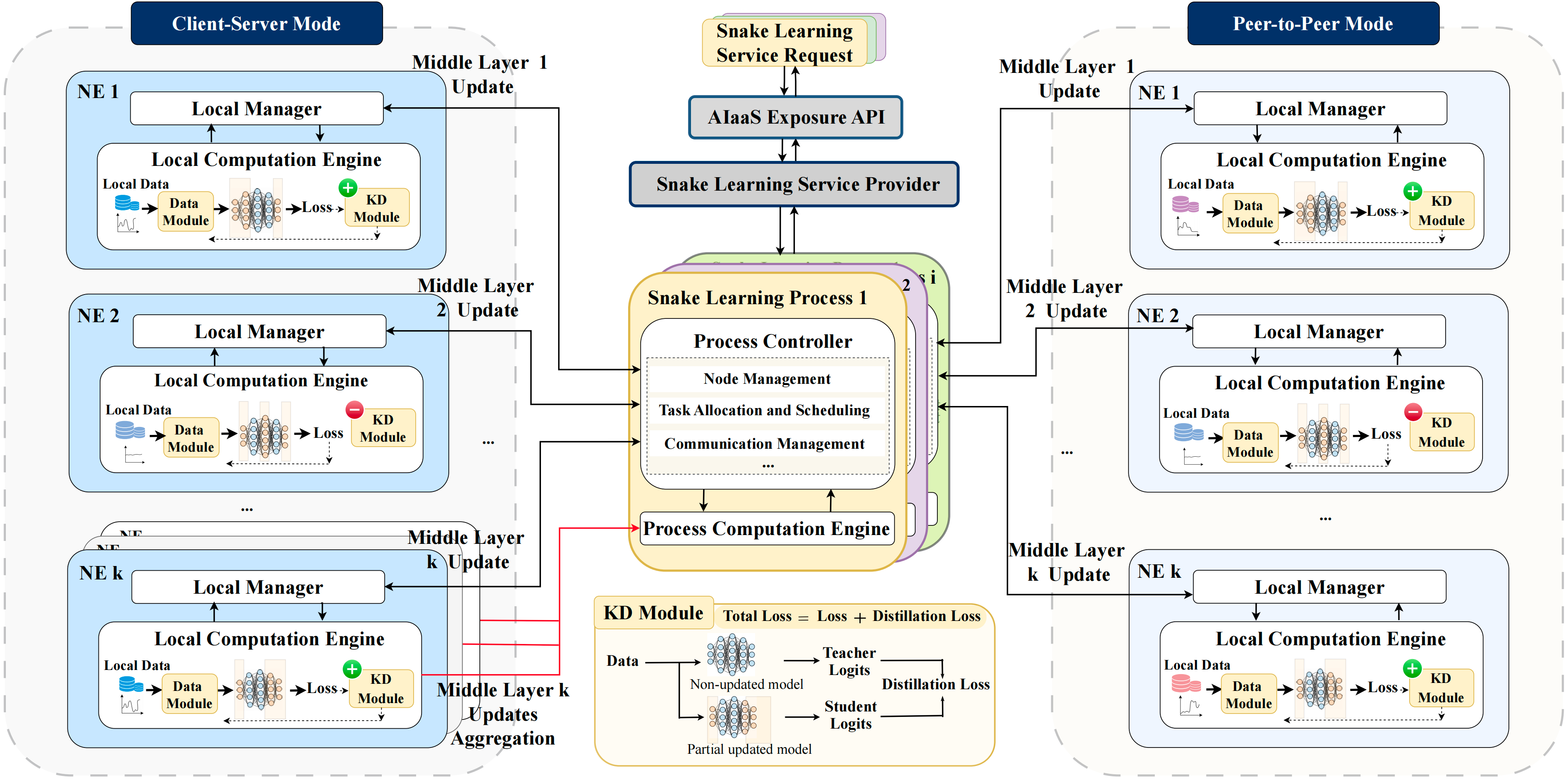
图2: Snake Learning 工作流程
Snake Learning 的主要组件
- 服务提供者(Service Provider,SP): 服务提供者(SP)负责Snake Learning中的训练任务管理和资源分配。它可以根据需要启动虚拟计算资源(如虚拟机或容器),以同时支持多个AI任务。在系统层面,SP可以根据服务需求和网络状况动态调整各任务的执行节点,以确保计算资源的高效利用。
- 过程控制器与计算引擎(Process Controller & Process Computation Engine,PC & PCE): 每个Snake Learning任务配备一个PC和一个PCE。PC负责任务分配和网络资源管理,比如节点的管理和任务调度;PCE则具体负责数据处理、模型训练和参数更新等计算工作。
- 本地管理器与本地计算引擎(Local Manager & Local Computation Engine,LM & LCE): 本地管理器(LM)负责管理每个节点的Snake Learning服务。在节点加入网络之前,LM需要获得SP的授权。LCE则负责处理节点上的具体计算任务,例如数据预处理、模型训练和参数更新。
Snake Learning 的工作流程
初始化: 在Snake Learning的过程中,SP首先通过AIaaS API注册学习任务,确定任务目标、需求及可能的约束(例如服务级协议、数据和设备、层的分配等)。接下来,PC负责对服务节点进行统一的管理,确认节点连通性、计算资源状况,并持续监控节点的性能指标,包括资源利用率、数据质量及训练状态。
层分配: 在Snake Learning中,PC基于各节点的计算能力、网络连接状态(如延迟和带宽)、系统资源(如CPU和内存)等因素,将模型的不同层分配给各节点进行训练。层分配的目的是根据节点的计算能力及网络状况,为其分配适合的模型层,从而最大化节点利用效率。
本地训练:在层分配完成后,每个节点基于其本地数据集对被分配的模型层进行本地训练。与联邦学习类似,Snake Learning强调数据隐私的保护,只有训练后的模型参数才会传输至其他节点,而非实时同步所有节点的数据。为了进一步提高数据的隐私性,Snake Learning还可以引入差分隐私和同态加密等技术,防止在参数传输过程中发生数据泄露。此外,每个节点会对数据进行标准化和增强处理,以提高模型的泛化能力。在数据不均衡或者数据特性差异明显的情况下,使用数据模块进行预处理。为了解决由于节点之间数据分布不同(Non-IID)而导致的训练不稳定性,Snake Learning引入了知识蒸馏(Knowledge Distillation, KD)模块。在训练过程中,KD模块对来自不同节点的知识进行融合,确保模型不会因数据差异而遗忘部分重要的特征信息。这种机制通过衡量各节点之间的数据分布差异触发跨节点知识的蒸馏与共享,保持模型的整体一致性和泛化能力。
节点管理与容错机制:由于6G网络中节点的状态具有动态性,可能因设备移动、连接波动等因素出现节点失效或网络中断的情况。为此,Snake Learning设计了动态任务管理与节点替换机制。PC会持续监控每个节点的状态,如果某节点发生故障,PC会将其训练任务转移至其他具有足够计算能力的候选节点来确保训练的连续性和模型的稳定性。
参数传输与节点管理: 在模型训练过程中,如果需要一定程度聚合则在参数服务器模式下每个节点在完成本地训练后将更新后的参数上传至PCE,由其负责参数聚合并分发至PC指定的下一个节点;否则,在点对点模式下,节点可以直接将参数传递至下一个目标节点,从而进一步减少通信延迟和系统复杂度。
主要实验结果
为了验证Snake Learning的有效性,研究通过在经典分类任务和大型模型微调任务上分别进行了实验,结果显示Snake Learning表现出色,尤其是在资源受限的6G网络环境中展现了巨大的优势。
- 分类任务的训练: 在VGG11模型、CIFAR-10数据集上的实验表明,相较于其他算法,Snake Learning (SL)通过较少的训练迭代次数更迅速地达到60%的准确率,显著提升了节点的训练效率。同时,Snake Learning在大幅降低了每次通信的开销的同时,最终性能超过了传统联邦学习的95%以上。

图 3 : 不同训练总设备迭代次数下Snake Learning和其他算法的分类准确度性能比较,其中Non-iid数据服从$\alpha=2$的Dirichlet分布.
- 大语言模型(LLM)微调: 对于如Llama-3 8B和OPT-1.3B大语言模型,Snake Learning通过将模型层分配给不同的节点训练大幅降低了内存占用和计算需求。例如,在优化OPT-1.3B模型时,传统联邦学习需要大约19.37GB的内存,而Snake Learning仅需3.13GB,大大降低了硬件要求。

图 4: FL和Snake Learning (SL)分别在24个节点数量下微调OPT-1.3B模型和32个节点数量下微调Llama-3 8B模型的性能比较,其中性能由perplexity (ppl)衡量,其值越低表明模型的确定性和有效性越高。